반응형
엘라스틱서치(elasticsearch) 샘플데이터 로딩
1. Home > Add data > Sample data 에서 추가.
2. Add data

3. View Data

4. 샘플데이터 조회
GET /kibana_sample_data_ecommerce/_search
GET /kibana_sample_data_flights/_search
GET /kibana_sample_data_logs/_search

반응형
'카페에서 IT 산책 (일반) > Elasticsearch & kibana' 카테고리의 다른 글
| Elasticsearch health check (엘라스틱서치 헬스 체크) (0) | 2023.09.06 |
|---|---|
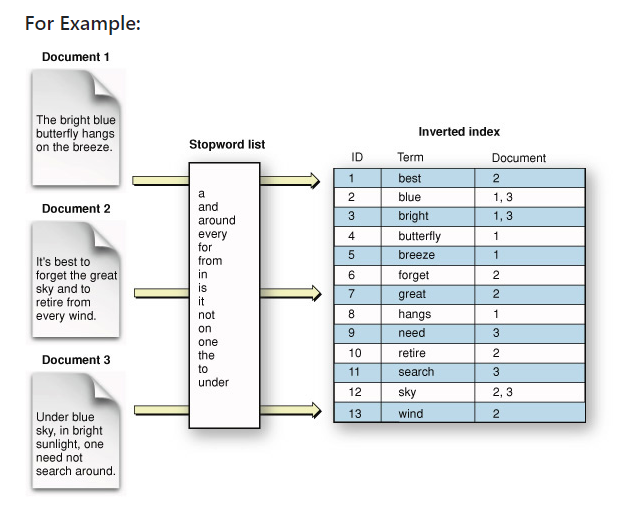
| 역색인 (inverted index) 구조 (0) | 2023.08.07 |
| kibana 7.9.3 설치 mac m1 (mac os 키바나 설치) (0) | 2023.02.05 |